Evidence Base
From multiple documents to a signed deliverable.One grid.
Upload your documents. Ask your questions. Every answer comes back cited, confidence-scored, and traced to the exact page. Review in one grid. Sign off and deliver.
The problem
Manual review does not scale.And AI makes the gap worse.
When the document set is large, thorough manual review becomes unrealistic. Something gets skimmed. Something gets missed. The larger the set, the more likely that becomes.
Review quality depends on who checked the work, what they noticed, and how much time they had. That is not a process. That is hope.
AI speeds up production but without a structured source layer, it can make the problem harder to catch. Teams may not know which source an answer relied on, whether that source was current, or whether another document said something different. The answer sounds confident. The inputs were never checked.
By the time someone finds out, the work is already in front of a client, partner, regulator, or decision-maker.
What changes
The speed of AI.The rigour of a structured review.
Days → Minutes
What used to take days of manual reading across a document set runs in minutes. Every document, every question, in parallel. The time your team gets back goes into judgment, not reading.
Nothing skipped
Every document gets every question. Not the ones someone had time for, or noticed, or thought were relevant. Every single one, with the same rigour across the whole set.
Side by side
The grid puts every document's answers next to each other. Spot differences, gaps, and contradictions at a glance instead of cross-referencing by hand across tabs and printouts.
How it works
Documents as rows. Questions as columns. Every cell answered and cited.
You upload your documents and ask your questions. Qonera runs every question against every document independently. The result is a grid where each cell is one document crossed with one question, answered by three AI models working separately, with the strongest evidence cited.
Each cell shows a confidence level based on how much the models agreed. High confidence means all three aligned on the same answer from the same evidence. Lower confidence flags it for your reviewer. Nothing gets quietly wrong.
The output quality does not depend on who ran the analysis or how much time they had. The same questions, the same models, the same standard, every time.
The process
Four steps from documents to signed answers
01
Upload
Drag in your documents. PDFs, scanned files, data exports. Everything is indexed into your Evidence Base the moment it arrives. Scanned files without a text layer are extracted automatically.
02
Index
Each document is indexed the moment it is added. Text is extracted, chunked, and stored so every question can search across the full content of every file.
03
Ask
Add your questions as columns. Each question runs across every document independently. Three AI models work in parallel per cell, with no cross-contamination between them.
04
Cite and sign off
Every cell answer is traced back to a specific file, page, and passage. Reviewers click any citation to open the source. Sign off the grid when you are satisfied. The audit trail is complete.
Under the hood
Built for documents that resist easy answers
Hybrid retrieval
Keyword and semantic search combined. Finds the right passage even when the wording in your question doesn't match the wording in the document.
BM25 full-text search and vector similarity run in parallel. Results are merged and ranked by relevance. Nothing gets missed because of phrasing.
OCR for scanned documents
Scanned PDFs with no text layer are extracted and indexed automatically. Older filings, court documents, leases, and historical reports work the same as native PDFs.
When standard text extraction returns nothing meaningful, Qonera falls back to vision-based OCR. The result is cached so you only pay for extraction once.
Multi-source citations
Each cell answer can cite up to three passages from across the document. Click any citation chip to jump to that exact page with the passage highlighted.
Citations are deduped and ranked by model confidence. The strongest evidence leads. Reviewers can trace every claim back to its source in one click.
Three-model confidence scoring
Every cell answer reflects how much three independent AI models agreed. High confidence means all three reached the same conclusion from the same evidence.
Models run with no cross-contamination. Disagreement is surfaced, not hidden. Lower confidence flags the cell for reviewer attention rather than quietly returning a single answer.
The grid
Every answer. Every source. Every disagreement surfaced. Ready to sign off.
Each cell is a document crossed with a question. Click any cell to open the inspection panel: see the cited passage, the page it came from, and whether all three models agreed.
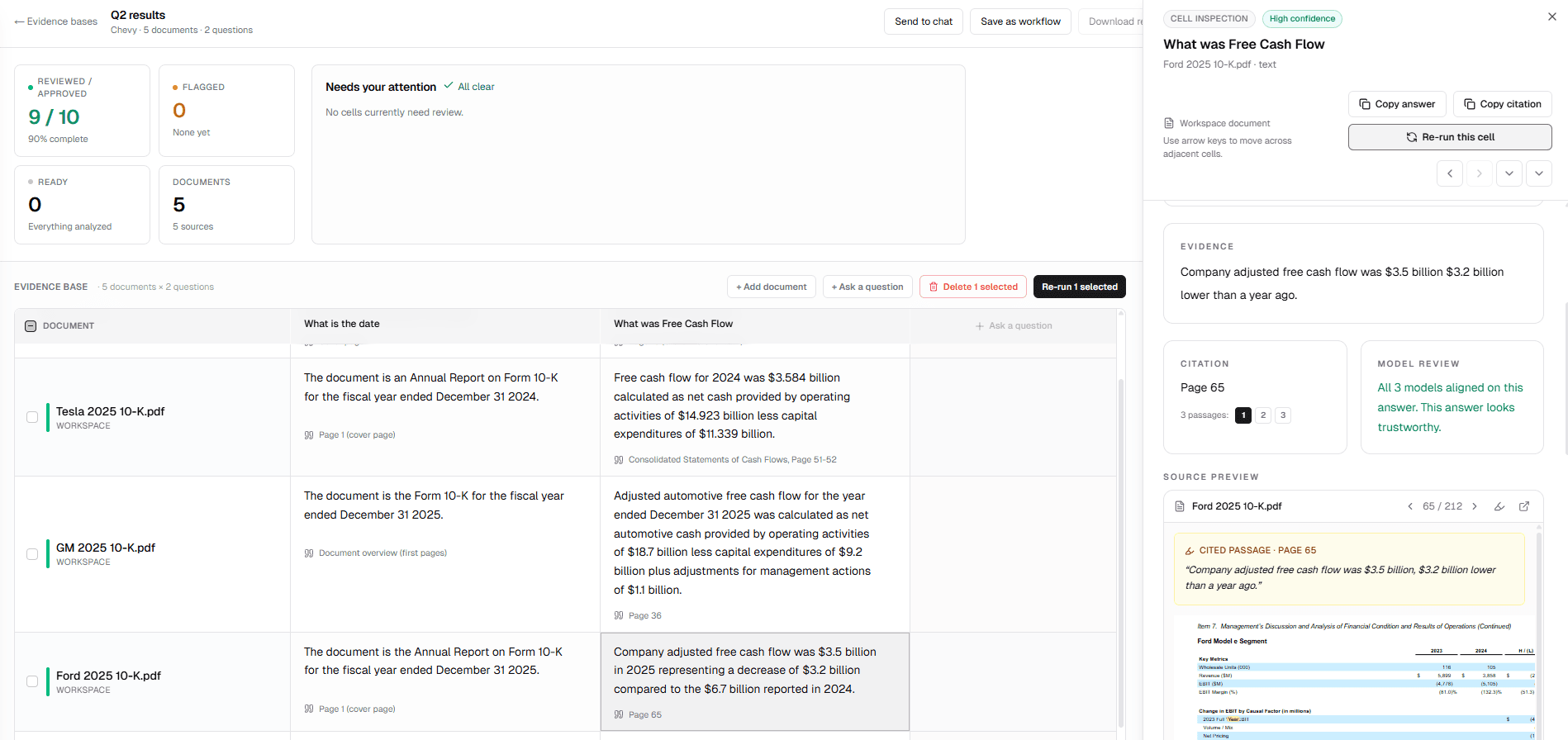
Confidence rating
High, medium, or low based on how much the three models agreed on the answer.
Citation chip
Page number and source file. Click to open the PDF at that exact location.
Cited passage
The exact text the answer was drawn from, highlighted in the source document.
Model review
"All 3 models aligned on this answer." Or a flag when they diverged.
Compliance
Every run is logged. Every source is recorded. Every sign-off is named.
Every Evidence Base run generates a tamper-evident audit record: which documents were in the source set, which models ran, what each model returned, and who reviewed and approved the output. The record cannot be edited after the fact.
Built to support the practical controls the EU AI Act pushes toward for human oversight, traceability, and documented review in professional AI systems. Compliance is a byproduct of doing the work, not a separate exercise.
See our AI Governance page →Get started
Every answer. Every source.
Every disagreement surfaced.
Run it on your own documents and see what comes back.